딥러닝과 데이터
데이터에서 중요한 것
- '필요한' 데이터가 얼마나 많은가
- 얼마나 효율적으로 사용되게끔 가공되었는지
⇒ 한쪽으로 치우치지 않고, 불필요한 정보를 가지고 있지 않으며, 왜곡되지 않은 데이터
- 딥러닝에 쓸 수 있도록 잘 정제된 데이터 형식으로 바꾸어야 함
- 데이터 분석에 가장 많이 사용하는 파이썬 라이브러리: pandas, matplotlib
딥러닝을 구동하려면 반드시 속성과 클래스를 먼저 구분해야 함
matplotlib을 이용해 그래프로 확인하기
matplotlib : 파이썬에서 그래프를 그릴 때 가장 많이 사용되는 라이브러리
seaborn : 각 정보끼리 어떤 상관관계가 있는지 알 수 있는 라이브러리
heatmap()함수 : 각 항목 간의 상관관계를 나타내는 함수
-두 항목씩 짝을 지은 뒤 각각 어던 패턴으로 변화하는지를 관찰하는 함수
⇒ 전혀 다른 패턴으로 변화하고 있으면 0, 서로 비슷한 패턴으로 변할수록 1에 가까운 값 출력
이렇게 결과에 미치는 영향이 큰 항목을 발견하는 것이 데이터 전처리 과정의 한 예시임
[데이터 전처리에 포함되는 과정]
: 데이터에 빠진 값이 있으면 평균이나 중앙값으로 대치
: 전혀 관계없는 이상 데이터가 있는지
: SVM, RF 등의 머닝러신 기법은 중요한 속성을 뽑아 내는 Feature extraction과정도 전처리에 포함
: 딥러닝은 중요한 속성을 내부적으로 뽑아내므로 위의 과정이 필요 없음
random() 함수: 미리 내장된 수많은 '랜덤 테이블' 중 하나를 불러내는 것
seed값 설정: 랜덤 테이블 중에서 몇 번째 테이블을 불러와 쓸지 정하는 것
⇒ 동일한 랜덤 값 출력
sklearn 라이브러리의 train_test_split() 함수
: 불러온 X 데이터와 Y 데이터에서 각각 정해진 비율(%)만큼 구분하여 학습셋과 테스트셋으로 나누는 함수
k겹 교차 검증(k-fold cross validation)
데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고, 나머지를 모두 합해서 학습셋으로 사용
⇒ 갖고 있는 데이터의 100%를 테스트셋으로 사용 가증

#앞서 저장한 모델보다 나아졌을 경우에만 저장 : save_best_only=True
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)다중 분류 문제
다중 분류(multi classification) : 여러 개의 답 중 하나를 고르는 분류 문제
- 클래스가 여러개
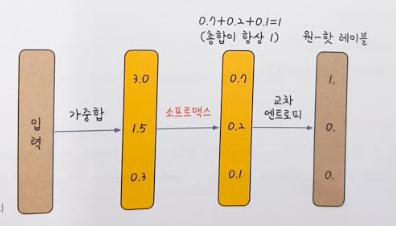
원-핫 인코딩: 여러 개의 Y값을 0과 1로만 이루어진 형태로 바꾸어 주는 것
소프트맥스(softmax): 총합이 1인 형태로 바꾸어 계산해 주는 활성화 함수. 합계가 1인 형태로 변환하면 큰 값이 두드러지게 나타나고 작은 값은 더 작아짐
⇒ 이 값이 교차 엔트로피(오차 함수)를 지나면 우리가 원하는 원-핫 인코딩 값을 갖게 됨
머신러닝 or 딥러닝을 위해 주어진 데이터의 답을 구하는 문제
1. 여러개 중에 정답을 맞치는 문제
2. 가격, 성적 같은 수치를 맞히는 문제 ⇒ 선형 회귀 문제
선형 회귀 실행
선형 회귀 데이터는 마지막에 참과 거짓을 구분할 필요가 없으므로, 출력층에 활성화 함수를 지정할 필요 없음
[자연어 처리를 위해 텍스트를 전처리하는 과정]
자연어: 우리가 평소에 말하는 음석이나 텍스트
자언어처리(Natural Language Processing, NLP) : 음성 또는 텍스트를 컴퓨터가 인식하고 처리하는 것
1) 텍스트의 토큰화
- 토큰(token): 텍스트를 단어별, 문장별, 형태소별로 나눈 단위
- 케라스의 text_to_word_sequence()함수를 사용하면 토큰화 가능
- 케라스의 Tokenizer()함수를 사용하면 단어의 빈도수를 쉽게 계산 가능
2) 단어의 one-hot encoding
: 단어가 문장의 다른 요소와 어떤 관계를 가지고 있는지 알아보는 방법
: 각 단어를 모두 0으로 바꾸어 주고 원하는 단어만 1로 바꾸어 주는 것
(파이선 배열의 인덱스가 0부터 시작하는 것을 주의)
one-hot encoding을 그대로 사용하면 벡터의 길이가 너무 길어지는 단점이 있음
이런 공간적 낭비를 해결하기 위해 단어 임베딩(word embedding)이 도입됨
3. 단어 임베딩
: 주어진 배열을 정해진 길이로 압축시키는 것
: 각 단어의 유사도를 계산했기 때문에 가능한 결과

위의 그림은 같이 원-핫 인코딩을 이용해 만든 16차원 벡터를 단어 임베딩을 통해 4차원 벡터로 바꾼 예시
⇒ 밀집된 정보를 가지고, 공간의 낭비가 적다는 것을 알 수 있음
*단어 간 유사도 계산하는 방법
: 오차 역전파를 이용하여, 최적의 유사도를 계산하는 학습 과정을 거침
: Embedding(입력될 단어 수, 출력되는 벡터크기, input_length=매번 입력할 단어 수) 함수 이용
4) 텍스트를 읽고 긍정, 부정 예측하기
1. 짧은 리뷰 10개를 불러와 각각 긍정이면 1이라는 클래스, 부정적이면 0이라는 클래스 지정
2. 문장을 토큰화
3.길이를 똑같이 맞춰 주는 패딩(padding)작업
*딥러닝 모델에 입력을 하려면 학습 데이터의 길이가 동일해야 함
4. 단어 임베딩
5. 딥러닝 모델 만들어 결과 출력


{'너무': 1, '재밌네요': 2, '최고예요': 3, '참': 4, '잘': 5, '만든': 6, '영화예요': 7, '추천하고': 8, '싶은': 9, '영화입니다': 10, '한': 11, '번': 12, '더': 13, '보고싶네요': 14, '글쎄요': 15, '별로예요': 16, '생각보다': 17, '지루하네요': 18, '연기가': 19, '어색해요': 20, '재미없어요': 21} [[1, 2], [3], [4, 5, 6, 7], [8, 9, 10], [11, 12, 13, 14], [15], [16], [17, 18], [19, 20], [21]] [[ 0 0 1 2] [ 0 0 0 3] [ 4 5 6 7] [ 0 8 9 10] [11 12 13 14] [ 0 0 0 15] [ 0 0 0 16] [ 0 0 17 18] [ 0 0 19 20] [ 0 0 0 21]] Epoch 1/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6952 - accuracy: 0.3000 Epoch 2/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6928 - accuracy: 0.5000 Epoch 3/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6905 - accuracy: 0.6000 Epoch 4/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6881 - accuracy: 0.6000 Epoch 5/20 1/1 [==============================] - 0s 1ms/step - loss: 0.6858 - accuracy: 0.7000 Epoch 6/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6834 - accuracy: 0.8000 Epoch 7/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6811 - accuracy: 0.8000 Epoch 8/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6788 - accuracy: 0.9000 Epoch 9/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6765 - accuracy: 0.9000 Epoch 10/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6741 - accuracy: 0.9000 Epoch 11/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6718 - accuracy: 0.9000 Epoch 12/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6695 - accuracy: 0.9000 Epoch 13/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6672 - accuracy: 0.9000 Epoch 14/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6648 - accuracy: 0.9000 Epoch 15/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6625 - accuracy: 0.9000 Epoch 16/20 1/1 [==============================] - 0s 2ms/step - loss: 0.6602 - accuracy: 0.9000 Epoch 17/20 1/1 [==============================] - 0s 1ms/step - loss: 0.6578 - accuracy: 0.9000 Epoch 18/20 1/1 [==============================] - 0s 1ms/step - loss: 0.6555 - accuracy: 0.9000 Epoch 19/20 1/1 [==============================] - 0s 1ms/step - loss: 0.6531 - accuracy: 0.9000 Epoch 20/20 1/1 [==============================] - 0s 1ms/step - loss: 0.6507 - accuracy: 0.9000 1/1 [==============================] - 0s 1ms/step - loss: 0.6484 - accuracy: 0.9000 Accuracy: 0.9000
⇒ 10개의 리뷰 중 9개의 긍정, 부정을 맞췄음을 확인